RAFT常见问题与解答
假设在网络被划分的同时选出了一个新的领导者,但是旧的领导者在不同的划分中。老领导怎么知道停止提交新条目?
旧领导要么无法获得大多数成功响应(如果它在少数分区中),要么如果它可以与多数节点通信的话,则多数节点必然会与新领导的多数重叠,重叠中的服务器将告诉旧领导有一个更高的term任期。这将导致旧的领导者转变为追随者。
Raft为了实现简单,牺牲了哪些特性?
- 为了持久化,每个操作都必须写入磁盘;可能需要在每个磁盘写入操作中批处理许多操作;
- 从leader到每个follower只能有一个有效的log follower拒绝无序的AppendEntries,leader的nextIndex[]机制需要一次一个逐步发送log。为大量的AppendEntries提供管道持续发送机制更好。
- 快照设计只适用于相对较小的状态,因为它将整个状态写入磁盘。如果状态是大的(例如,如果是一个大的数据库),你可能需要一种方法来只编写最近更改的状态的一部分。
- 类似地,通过向复制副本发送完整的快照使其恢复到最新状态将非常缓慢,如果复制副本已经有旧的快照,则这是不必要的。
- 服务器可能无法充分利用多核的优势,因为操作必须一次执行一个(按日志顺序)
客户端进行交互,section 8

关于领导者需要提交一个空白的没有任何操作的条目(no-op条目)以便知道哪些条目被提交的一行,为什么要这么做?
问题情况如图8所示,如果S1在(b)之后成为leader,它无法知道它的最后一个日志条目(2)是否已提交。最后一个日志条目不会被提交的情况是,S1立即失败,并且S5是下一个领导者;在这种情况下,S5将强制所有对等方(包括S1)拥有与S5的日志相同的日志,而S5的日志不包括条目2。
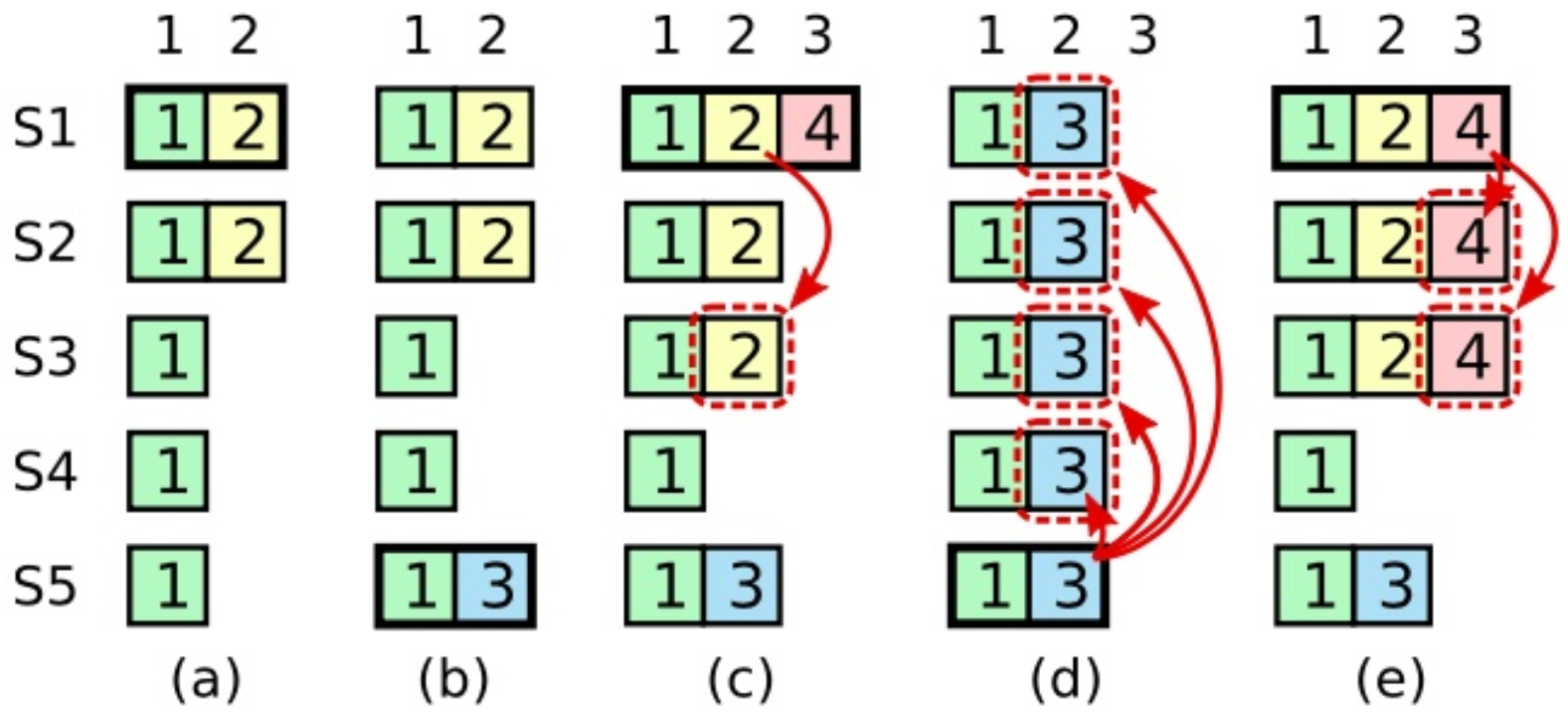
但是假设S1在其任期(任期4)内提交了一个新条目。如果S5看到新条目,S5将从其日志中删除3并在其位置接受2。如果S5没有看到新的条目,当S1崩溃时,S5无法竞选成功下一任leader,因为它将无法通过选举限制。无论哪种方式,一旦S1在其任期内提交了一个新条目,它就可以正确地断定其日志中的每个前面的条目都已提交。(看Raft log中的内容,提交成功则代表大多数follower与leader的日志是一致的)
第8节末尾的no op讨论的是一种优化,在这种优化中,领导者执行并回答只读命令(例如get(“k1”)),而不在日志中提交这些命令。例如,对于get(“k1”),领导者只需在其键/值表中查找“k1”,并将结果发送回客户机。如果leader刚刚选举成功,那么它的日志末尾可能有一个put(“k1”,“v99”)。领导者应该将“v99”发送回客户机,还是发送回领导者的键/值表中的值?首先,leader不知道v99日志条目是提交的(并且必须返回给客户机)还是未提交的(并且不能返回)。因此(如果是使用此优化),新的Raft leader首先尝试向日志提交no op;如果提交成功(即,leader没有崩溃),那么,leader拥有在此提交点之前的所有日志。(译者:日志均是提交状态的)
日志的复制
AppendEntries RPC:
被领导者调用 用于日志条目的复制,同时也被当做心跳使用;
实际上不仅是用来发送从Client发送给Leader的命令,也可以用来让follower进行日志的统一。
prevLogIndex、prevLogTerm理解:

本文标题:RAFT常见问题与解答
文章作者:小师
发布时间:2021-04-09
最后更新:2022-05-04
原始链接:chunlife.top/2021/04/09/RAFT常见问题与解答/
版权声明:本站所有文章均采用知识共享署名4.0国际许可协议进行许可